




Adopting Standardized Identification and Metadata
Since it’s becoming all the rage, I decided to go legit and get myself (and my blog) a standard ID and enable the site for easy metadata exchange.
OpenID
OpenID is an open and free framework for users (and their blogs or Web sites) to establish a digital identity. OpenID starts with the concept that anyone can identify themselves on the Internet the same way websites do via a URI and that authentication is essential to prove ownership of the ID.
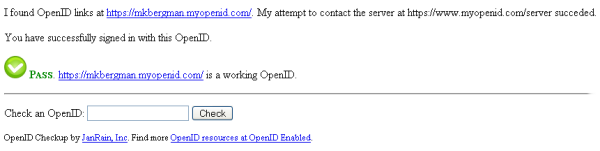
Sam Ruby provides a clear article on how to set up your own OpenID. One of the listing services is MyOpenID, from which you can get a free ID. With Sam’s instructions, you can also link a Web site or blog to this ID. When done, you can check whether your site is valid; you can do a quick check using my own ID (make sure and enter the full URI!). However, to get the valid ID message as shown below, you will need to have your standard (and secure) OpenID password handy.
unAPI
unAPI addresses a different problem — the need for a uniform, simple method for copying rich digital objects out of any Web application. unAPI is a tiny HTTP API for the few basic operations necessary to copy discrete, identified content from any kind of web application. An interesting unAPI background and rationale paper from the Ariadne online library ezine is “Introducing unAPI”.
To invoke the service, I installed the unAPI Server, a WordPress plug-in from Michael J. Giarlo. The server provides records for each WordPress post and page in the following formats: OAI-Dublin Core (oai_dc), Metadata Object Description Schema (MODS), SRW-Dublin Core (srw_dc), MARCXML, and RSS. The specification makes use of LINK tag auto-discovery and an unendorsed microformat for machine-readable metadata records.
Validating the call is provided by the unAPI organization, with the return for this blog entry shown here (which is error free and only partially reproduced):
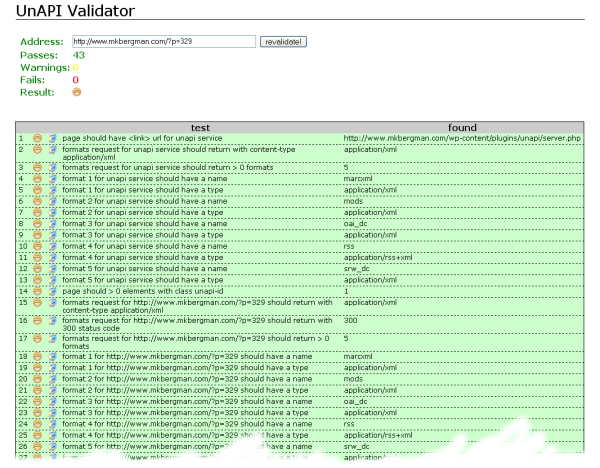
The actual unAPI results do not appear anywhere in your page, since the entire intent is to be machine readable. However, to show what can be expected from these five formats, I reproduce what the internal metadata listings for the five different formats are in these links:
MARCXML:
MODS:
OAI-DC:
RSS:
SRW-DC:
unAPI adoption is just now beginning, and some apps like the Firefox Dublin Core Viewer add-on do not yet recognize the formats. But, because the specification is so simple and is being pushed by the library community, I suspect adoption will become very common. I encourage you to join!
